赛优市场店员积累了丰富的神秘顾客经验,严谨,务实,公平,客观.真实的数据支持!


发布日期:2024-03-13 09:18 点击次数:53
基于大模子的Agent,还是成为了大型的博弈游戏的高等玩家北京神秘顾客,何况玩的如故德州扑克、21点这种非圆善信息博弈。
来自浙江大学、中科院软件所等机构的野心东说念主员提议了新的Agent进化政策,从而打造了一款会玩德州扑克的“阴恶”智能体Agent-Pro。
通过不停优化自我构建的全国模子和行径政策,Agent-Pro掌持了虚张威望、主动消灭等东说念主类高阶游戏政策。

Agent-Pro以大模子为基座,通过自我优化的Prompt来建模游戏全国模子和行径政策。
比拟传统的Agent框架,Agent-Pro大要变通地应付复杂的动态的环境,而不是仅专注于特定任务。
何况,Agent-Pro还不错通过与环境互动来优化我方的行径,从而更好地杀青东说念主类设定的想法。
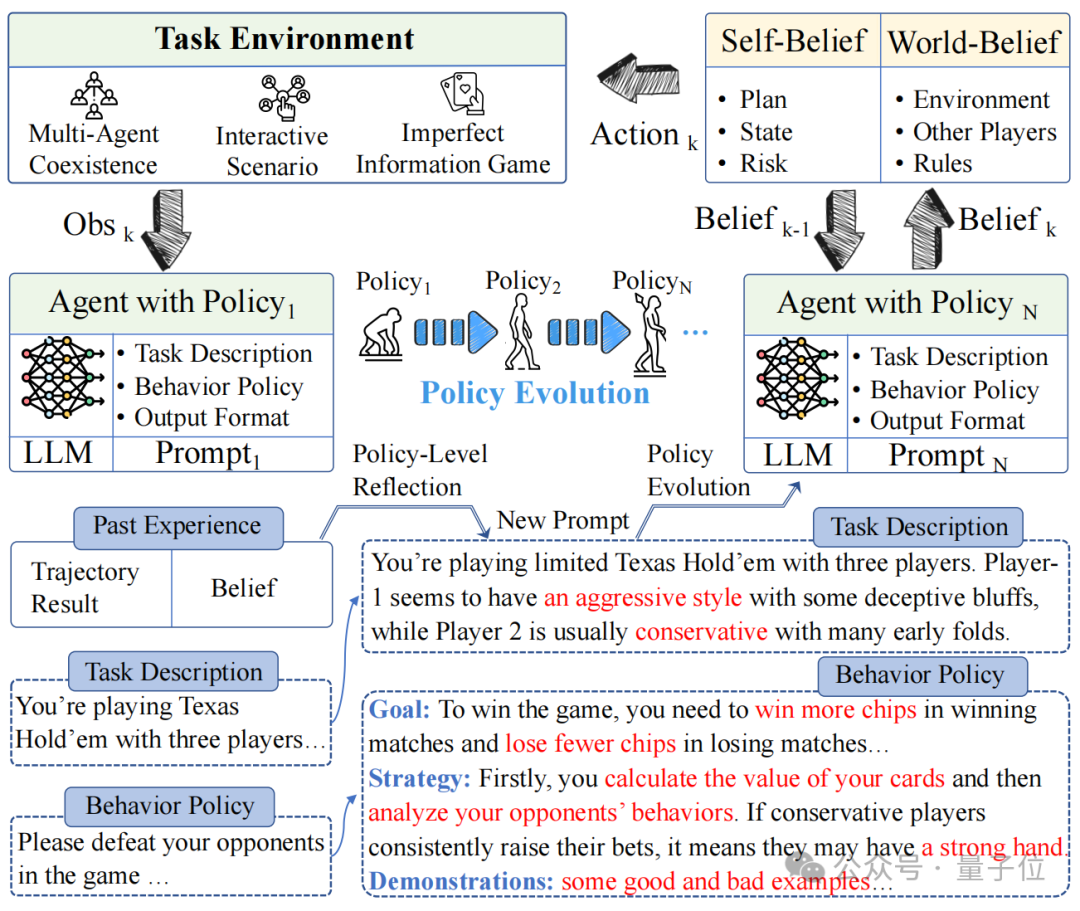
同期作家还指出,在竞争、公司谈判和安全等践诺全国中碰到的情景,大多不错综合为multi-agent博弈任务,而Agent-Pro通过对这类情境的野心,为责罚繁密践诺全国的问题提供了灵验政策。
那么,Agent-Pro在博弈游戏中的阐发究竟何如呢?
进化出游戏全国模子
在野心中,作家使用了“21点”和“有限注德州扑克”这两款游戏对Agent进行了评估。
领先简要先容下两个博弈游戏的基本端正。
21点
游戏中包含一个庄家和至少别称玩家。
玩家不错看到我方的两张手牌, 以及庄家的一张明牌,庄家还诡秘了一张暗牌。玩家需要决定是陆续要牌(Hit)如故停牌(Stand)。
游戏的想法是在总点数不卓绝21点的前提下,尽量使总点数卓绝庄家。
有限注德州扑克
游戏初始阶段为Preflop阶段,每位玩家将得到两张只属于我方且对其他玩家守秘的私牌(Hand)。
随后,会有五张环球牌面(Public Cards)秩序发出:领先翻牌(Flop)3 张,其次转牌(Turn)1张,临了是河牌(River)1张。
玩家有四种弃取:弃牌(fold)、过牌(check)、跟注(call)或加注(raise)。
想法是哄骗我方的两张Hand和五张Public Cards随便组合,尽可能构造出最好的五张扑克牌组合。
在“21点”当中,不异是使用GPT-4作为基础模子,Agent-Pro的阐发卓绝了ReAct框架。
在手牌交流的情况下,二者的阐发如下图所示。
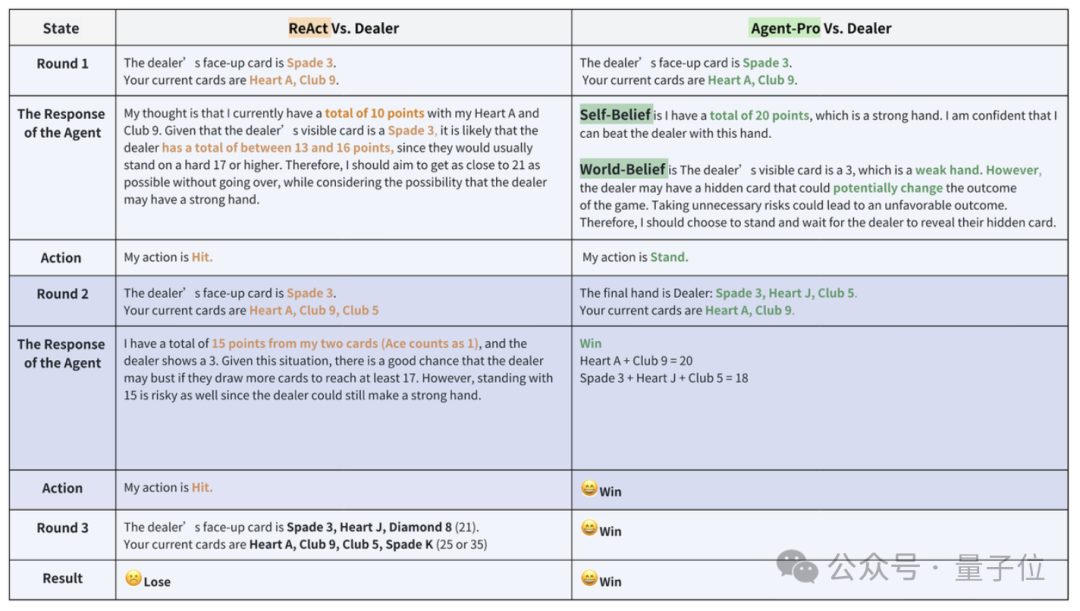
Agent-Pro通过分析得出自我信念(Self-Belief)和对外部全国的信念(World-Belief),正确执意到我方的手牌已接近21点,合理的弃取了停牌。
而ReAct则未能实时停牌,导致最终爆牌,输掉了游戏。
从游戏中大要看出Agent-Pro更好的泄露了游戏的端正,并给出了合理的弃取。
接下来再望望在德州扑克中Agent-Pro的阐发。
一次牌局中,参赛选手分离是教练后的DQN、DMC政策,原生GPT3.5和Agent-Pro(基于GPT-4),他们的手牌和环球牌如下图所示:

△
S、H、C、D分离代表黑桃、红桃、梅花、方块
在现时游戏情景(Current game state)下,Agent-Pro分析得出Self-Belief、World-Belief和最终的Action,并跟着游戏情景的变化,不停更新Belief,笔据本人和敌手的情况,作念出生动合理的弃取。

△
交流牌局团结位置的Baseline(原始大模子)成果为-13
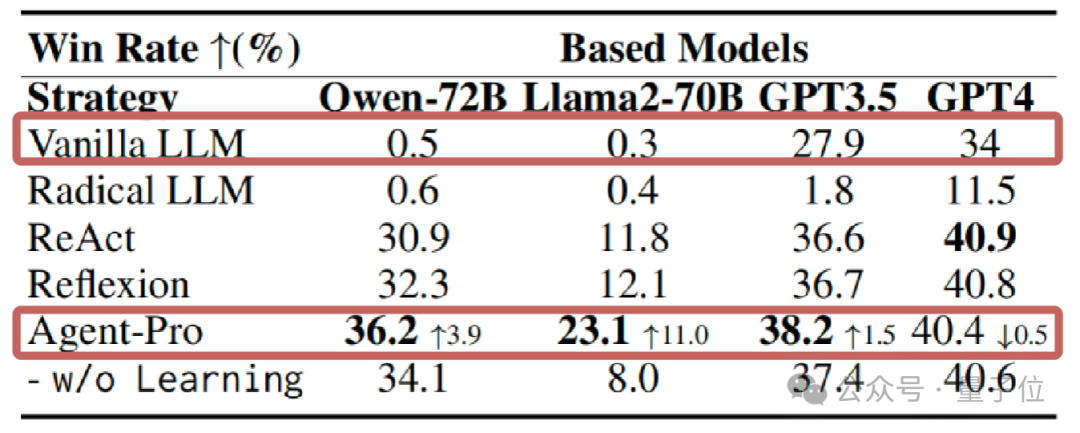
统计数据上看,21点游戏中,在使用GPT、Llama等多种大模子的情况下,Agent-Pro的阐发都显赫卓绝了原始模子和其他参与对比的Agents框架。
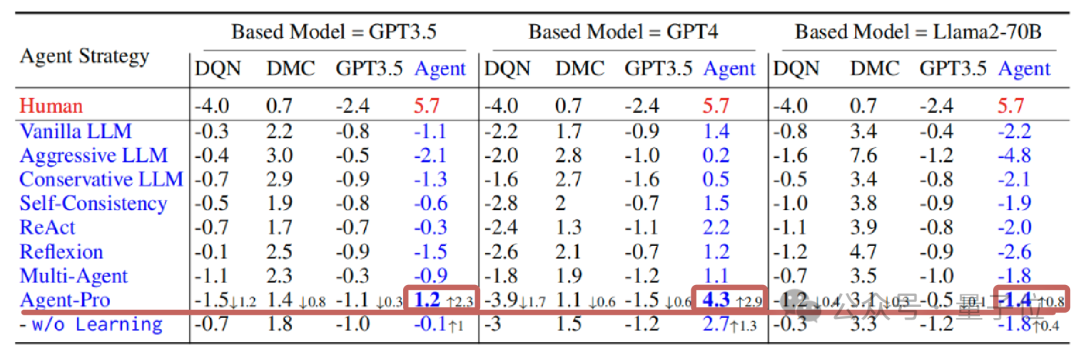
在更为复杂的德州扑克游戏中,Agent-Pro不仅卓绝了原始大模子,还打败了DMC等教练后的强化学习Agent。
那么,Agent-Pro是何如学习和进化的呢?
三管皆下升迁Agent阐发
Agent-Pro包括“基于信念的方案”“政策层面的反想”和“全国模子和行径政策优化”这三个组件。
基于信念的方案(Belief-aware Decision-making)
Agent-Pro笔据环境信息,领先酿成Self-Belief和World-Belief,然后基于这些Belief作念出方案(Action)。
在后续环境交互中,Agent-Pro动态更新Belief,进而使作念出的Action妥当环境的变化。
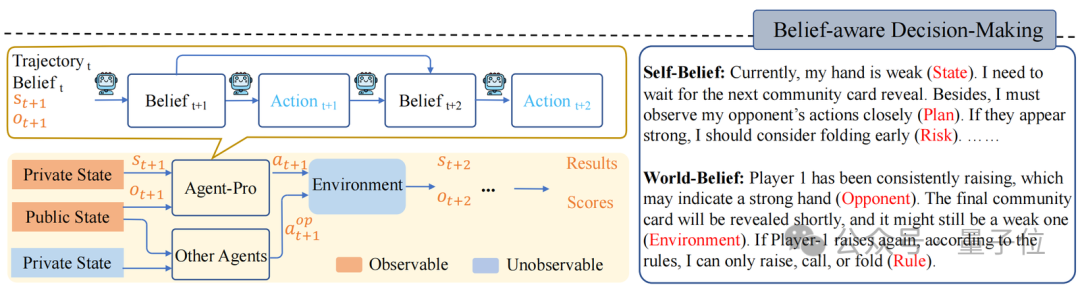
举例,德州扑克游戏中:
神秘顾客公司_赛优市场调研环境信息可包括手牌(Private State)、环球牌(Public State)、行径轨迹(Trajectory)等;
Agent-Pro敌手牌(State)、出牌筹商(Plan)及潜在风险(Risk)的预估等信息组成了它的Self-Belief;
而Agent-Pro对敌手(Opponent)、环境(Environment)和端正(Rule)的泄露则组成了它的World-Belief;
这些Belief在每一个方案周期中都会被更新,从而影响下个周期中Action的产生
政策层面的反想(Policy-Level Reflection)
与东说念主类一样,Agent-Pro 会从历史训戒、历史观点和历史成果中进行反想和优化。它自主调换我方的Belief,神秘顾客教程寻找有用的指示指示,并将其整合到新的政策Policy中。
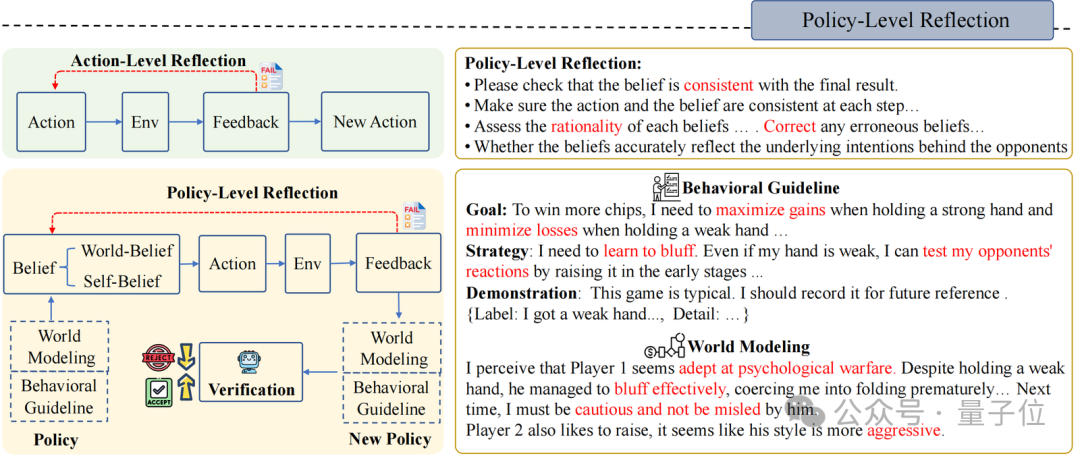
领先,Agent-Pro以笔墨的体式设想了一个对任务全国的建模以及对行径准则的形色, 他们所有被看成念Policy:
World Modeling:任务全国的建模,举例对游戏环境的泄露、敌手们的作风分析、环境中其他Agent的政策计算等;
Behavioral Guideline:行径准则的形色,举例对游戏想法的执意、我方政策运筹帷幄、曩昔可能濒临的风险等
其次,为了更新World Modeling和Behavioral Guideline,Agent-Pro设想了一个Policy-level Reflection经由。
与Action-level Reflection不同,在Policy-level的反想中,Agent-Pro被辅导去见原内在和外皮信念是否对皆最终成果,更紧迫的是,反想背后的全国模子是否准确,行径准则是否合理,而非针对单个Action。
举例,德州扑克游戏中Policy-level的反想是这么的:
在现时全国模子和行径准则(World Modeling & Behavioral Guideline)的领导下,Agent-Pro不雅察到外部情景,然青年景Self-Belief和World-Belief,临了作念出Action。但要是Belief不准确,则可能导致分歧逻辑的行径和最终成果的失败;
Agent-Pro笔据每一次的游戏来谛视Belief的合感性,并反想导致最终失败的原因(Correct,Consistent,Rationality…);
然后,Agent-Pro将反想和对本人及外部全国的分析整理,生成新的行径准则Behavioral Guideline和全国建模World Modeling;
基于更生成的Policy(World Modeling & Behavioral Guideline),Agent-Pro重迭进行交流游戏,来进行政策考证。要是最终分数有所升迁,则将更新后的World Modeling & Behavioral Guideline和保留在指示中。
其实,早在4年前,神秘顾客早已经在武汉开始出现了。
2005年春节前,春运开始后第三天,武汉大学副教授王长征博士和另5名学者,分别给汉口火车站的5个火车票代售点打电话“订票”。2月3日,适值春运高峰,他们又拎着大包小包来到汉口火车站,混迹于熙熙攘攘的人流中,从售票大厅到候车室,从贵宾室到出站口,“神出鬼没”般盘桓了两三个小时。2月4日,王长征将一份数千字的分析报告,传给了汉口火车站站长王祖祥。
全国模子和行径准则的优化(World Modeling & Behavioral Guideline Evolution)
在Policy-level Reflection之上,面对动态的环境,Agent-Pro还选拔了深度优先搜索(DFS)和政策评估,来接续优化全国模子和行径准则,从而找到更优的政策。
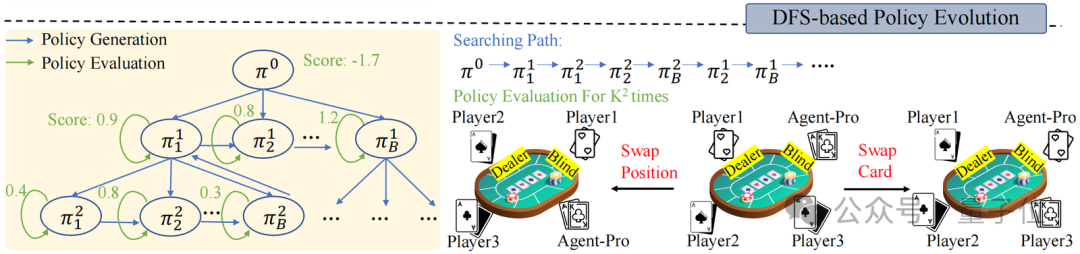
政策评估是指Agent-Pro 在新的采样的轨迹中对新Policy进行更全面的评估,从而教练新政策的泛化才气。举例,德州扑克游戏中,新采样多条游戏轨迹。
通过交换玩家位置或手牌,来排斥由于运说念带来的随即要素,从而更全面评估新政策的才气。
而DFS搜索则在新政策不成在新的场景中带来预期的检阅(政策评估)时使用,按照DFS搜索政策,从其他候选政策中寻找更优的政策。
— 完 —北京神秘顾客

Powered by 宁波神秘顾客调查 @2013-2022 RSS地图 HTML地图
Copyright 站群 © 2013-2022 粤ICP备09006501号
